Abstract
Aiming at the troubles (such as complex background, illumination changes, shadows and others on traditional methods) for detecting of a walking person, we put forward a new adaptive detection algorithm through mixing Gaussian Mixture Model (GMM), edge detection algorithm and continuous frame difference algorithm in this paper. In time domain, the new algorithm uses GMM to model and updates the background. In spatial domain, it uses the hybrid detection algorithm which mixes the edge detection algorithm, continuous frame difference algorithm and GMM to get the initial contour of moving target with big data, and gets the ultimate moving target with big data. This algorithm not only can adapt to the illumination gradients and background disturbance occurred on scene, but also can solve some problems such as inaccurate target detection, incomplete edge detection, cavitation and ghost which usually appears in traditional algorithm. As experimental result showing, this algorithm holds better real-time and robustness. It is not only easily implemented, but also can accurately detect the moving target with big data.
1. Introduction
Vision is an important way for humans to observe and recognize the world, and the majority of the external information are obtained by vision. This not only shows the visual information occupies major share, but also reflects the importance of visual function in people's daily life. Human gives computer a function like human vision. People use camera to get images and convert them into digital signals in order to use computer to process information, which is the process of computer vision emergence [1-4]. The IVS (Intelligent Video Surveillance) achieves video surveillance intelligent process by using computer vision technology to process, analyze and understand video signal so as to control the video monitoring system. At present, many places have applied the monitoring technology, but the actual operation and monitoring task are done still in the manual way, which lacks of intelligence. So, it may not bring good real-time performance because of man-made factors and lacks of the ability to handle some emergencies.
Video monitoring technology has gone three stages from analog era to digital era and network era. With the development of network technology, the IVS technology becomes the times requirements. It uses open architecture structure, and easily integrates with alarm, access control, patrol, management information system. Based on embedded technology, it has stable performance, good flexibility, and does not need the special management [6]. The IVS technology mainly includes detecting and tracking moving target with big data. The moving target with big data detection is an important subject to the computer vision information extraction, and it also is the foundation for video sequence movement analysis. Because it requires real-time detection and partition object, how to fast and accurately extract the moving object from video sequences is what we focus on. So far, there are mainly three kind methods to test moving object: Optical Flow method [7], inter-frame difference method [8] and background difference method [9]. The advantage of optical flow method is that it can detect the independence moving target with big data, and needn’t know any information about scene in advance. Its weak points are complexity, special hardware supported, and bad real-time performance; Background difference method is a frequently used method. Its basic idea is to compare the input image with the background image, through judging the changes of gray scale, or using the change of histogram and other statistics information to find outlier and to divide moving target with big data. Its weakness is sensitive to the change of external condition and difficult to recognize background; the inter-frame difference method is to subtract the corresponding pixel values on two adjacent frame images. In the case of condition luminance has little change, if the corresponding pixels value has less different, we would think this scenery is static. Otherwise, if some point pixel value has great change in some area, it would be thought that caused by moving object and those areas will be marked down to calculate the positions of moving object in the image. This algorithm is simple, easy implementation, and light change effect is relatively small. But the detected target contour may have cavitation. In addition to the above three methods, the application of edge detection method is also widespread. It is helpful to distinguish moving target with big data and extract the characteristics of moving target with big data. Its merit is great robustness to background noise. But its complexity is also relatively higher. The edge detection of moving images can be calculated by time and space difference. The space difference is to use various existing edge detecting algorithm. The time difference is to calculate the difference of continues frames, or to calculate the difference image of current image and background image.
Aiming at some problems such as cavitation, shadow, isolated noise, incomplete edge detection, and miss detection caused by object slowly moving, this paper puts forward a mixture adaptive detection algorithm including Gaussian Mixture Model (GMM), edge detection algorithm and continuous inter-frame difference algorithm, which is not just in edge detection – but in the detection of a walking person detection. This algorithm takes full advantage of the merit of each algorithm, adopting certain easily implemented background suppression algorithm and morphological processing to effectively overcome these problems and achieve a better result.
2. Related works
In recent years, video monitoring technology has produced obvious change tendency. It has transited from analog stage to digital stage, the standard is more open than before, the HD video monitoring has produced an enormous impact on the security and other fields, the integration and intelligence are gradually becoming mainstream. These changes have promoted the video monitoring technology to take a step toward mature stage.
The study of moving target with big data detection technology is relatively earlier and deeper in foreign countries. In recent years, a lot of research results also appear in china, which usually are based on movement feature or foreground extraction. In generally, the traditional moving target detection algorithm is mainly based on three basic detection algorithms. For optical flow method, Meyer improves the optical flow field by calculating the displacement vector to detecting the motion object, who also acquires a good result [10]. The reference [11] puts forward an improved optical flow computation method which is based on gradient. A new 3D-Sobel operator is used to calculate pixel space-time gradient. It can detect the moving target with big data owing to different speed, by adding confidence judgment operator to ascertain optical flow field of pixel corresponding. The background difference method relies on background extraction and effective background updating mechanism to determine the detection quality and effect. This method possesses prominent real-time and fast detection speed. However, it is sensitive to change of scene. Once background updating can’t keep up with the dynamic scene, it will produce seriously impact on detection result. Stauffer builds GMM for each image pixel and updates the model by linear approximation estimation. He obtains the Gaussian model distribution of background by evaluating the distribution of self-adaption GMM and classifies all pixels according to the Gaussian model distribution [12]. As for the inter-frame difference method, according to the predefined category, Lipton gets Luminance difference of adjacent frames by inter-frame difference method. He builds different threshold according to the different luminance difference to judge different moving target with big data such as vehicle and goers [13]. This method has better detection effect on complex background. It does not need to build background model and possesses fast speed. Its weak point is it is easy to be affected by movement speed and is sensitive to noise. In order to improve deficiency of inter-frame difference method, the reference [14] puts forward a mixture detection method combining the inter-frame difference method with the background subtraction method. This method gets one foreground image by three frame difference method which possesses edge information, gets another foreground image by background difference according to the improved mode algorithm, and then makes Boolean OR operation by using the two images get foreground target. It possesses great robustness.
In addition to the traditional moving target detection algorithm, some new emergence methods guide the new research direction. At present, this method based on statistics and learning will be more and more applied to moving target with big data detection, because it can well deal with the influence from noise, shadow and the light changes. W. Grimson uses distribution sensor to build vision monitor system. This system uses tracking data to correct sensor and builds background model. It classifies the detected moving target with big data in order to detect abnormal movement by studying the common features of different categories movement [15]. K. Witkin proposes a detection method based on parametric active contour model, which is widely applied in the computer vision. The parametric active contour model combined image feature with the cognition of human can fulfill the task of image understanding and recognition. Besides, every single method may have different defect and loophole, so many scholars puts forward lots of mixed algorithms in a variety of ways. By combining inter-frame difference method with background modeling technology, Robert T. Collins obtains a detection algorithm which possesses outstanding time performance [16]. Aiming at the camera movement, D. Murray makes global movement estimation by image matching which is based on the traditional differential method. Then he makes motion compensation for image complete the motion target detection [17]. Zhang D. G. applied the method of wavelet packet analysis in signal processing to moving target with big data detection, which produces good effect [18-20]. South China University of Technology researchers put forward a moving target with big data detection algorithm based on mixed condition random field model. It is applied to mobile robot vision detection system [21-23]. This method has accurate and stable merit. T. Ojala proposed a moving target with big data detection method based on optical flow and level set [24-26]. It can use target edge closed curve which can be obtain by the energy function to complete detection.
Based on the above analysis and description for the moving target with big data detection method, and contacting with some research ideas and methods of some researchers, we proposed a mixture algorithm which uses GMM to build and update background in time domain, and uses the combined method including edge detection algorithm and inter-frame difference algorithm and GMM to get the contour of initial movement object in spatial domain, and then gets the final moving target with big data by calculating further in this paper.
3. Ideology of our algorithm
Our algorithm mainly consists of the shadow suppression, the morphological processing and the mixed method including the mixture Gauss model, the inter-frame difference method and the edge detection algorithm. First, testing the sequence of image by using the algorithm that contained the inter-frame difference method and the edge detection algorithm, we can obtain an initial object contour. Then testing the sequence of image by using the Canny algorithm based on the mixture Gauss model, we can get another initial target contour. And calculating these two values with logical operation “OR”, finally, dealing the target image with morphology processing, in that way, we can get the ultimate target. The algorithm flow is as shown in Fig. 1.
Fig. 1The flow of our algorithm
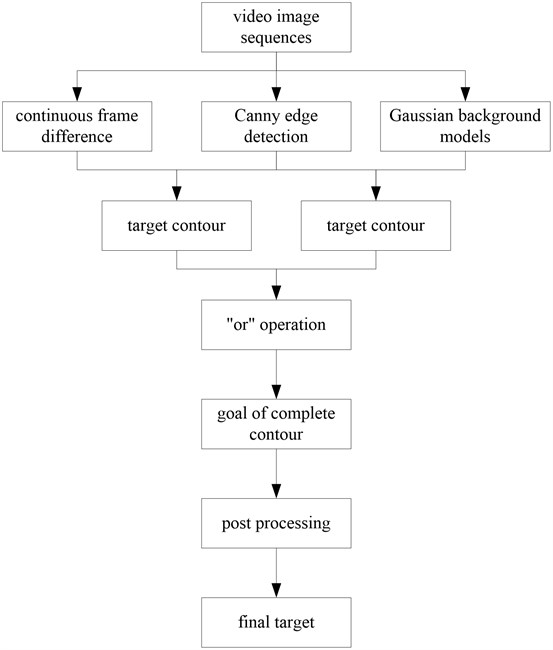
4. Principle of the basic methods
4.1. GMM
Lemma 1. For any pixel in background model of image, the background value of this pixel can be simulated by Gaussian distribution which is built according to the background model proposed by Stauffer. If this point value is at time , the probability of the point belonging to the background is:
In Eq. (2), represents the dimension number of the Gaussian distribution. represents the weight when the th Gaussian distribution at time . represents the average value when the th Gaussian distribution at time . represents the covariance when the th Gaussian distribution at time . represents the probability density of the th Gaussian distribution. The represents the corresponding weight of distribution. The Gaussian distribution always order by the priority from high to low. The is usually valued between 3 and 5, and it can be adjusted according to the storage capacity and computing power of computer.
Lemma 2. For the GMM, we can use the average gray and pixel variance of each pixel of image in a period video sequences to initialize the -dimension Gaussian distribution parameter:
It needs storage many video images to calculate and . If it has not higher initial requirement to Gaussian mixture parameter, and pixel values of each color channel among [0-255], we can directly initialize the larger variance to the Gaussian distribution. The average value and weight of th Gaussian distribution can be obtained from Eq. (4):
In order to improve real-time performance and reduce the memory requirement, we use the pixel values of the first frame image to initialize some Gaussian contribution in GMM, and then take the weight of Gaussian contribution, which is bigger than others. The average value of other Gaussian distribution takes 0 and the weight takes the same value. The variance of all Gaussian function takes larger initialized value in GMM. So, it has great probability in the process of mixture Gaussian parameter study to take Gaussian function which has greater weight as background.
Theorem 1. The parameter update of mixture Gaussian model consists of the parameter update of Gauss function, the weight update of each distribution and sorting each distribution is according to the weight value. After obtaining the new pixel value, we respectively match the pixel value of current frame with the Gaussian distribution. If the new obtained pixel value satisfied with judging formula, we reckon the is matched with the Gaussian function. The judging function is:
represents the average value of th Gaussian function, represents the user defined parameter which generally is taken as 25 in the practical application system. represents standard deviation of th Gaussian function in time 1. The matched Gaussian distribution parameter with is updated according the Eqs. (6)-(8):
represents learning rate that user defines, and . The size of determines the speed of background update, and the larger the is, the faster the update is. If has not matched Gaussian distribution, the Gaussian distribution which has the smallest weight will be updated by the new Gaussian distribution and the new distribution value is and will be initialized the larger standard deviation , and the smaller weight . The rest of Gaussian distribution maintains the same average value and variance, but their weights will be decreased. It is handled according to the for Eq. (9):
Theorem 2. After the parameter of mixture Gaussian model of each pixel in the image frames is updated, we order K Gaussian distribution, from the big to the small, which is the mixture Gaussian model composing each pixel according to the ration. The Gaussian distribution which is most likely to describe the stability background process will be located at the top in this sequence. But the distribution produced by the background turbulence will slide into the bottom of this sequence, and eventually is replaced by the Gaussian distribution assigned new values. Finally, the Gaussian distribution brought from background will be determined in mixture Gaussian model. We take the front Gauss distribution in the sequence as a background pixel model, where is:
In Eq. (10), represents predetermined threshold. It represents minimum weight proportion of background distribution. If is bigger, the background is indicated by using several Gaussian distribution. Otherwise, it will be indicated only by using one Gaussian distribution. The pixel value at the time is got by Eq. (11):
Using many Gaussian distribution to establish model for one pixel point, we can better deal with the multiple model area in video image. In this background area, their pixel values have great difference in different time. But it should not be detected as foreground. However, when we use many Gauss distribution to describe the pixel value of this position, it is allowed that this position appears many independent color areas. At the time to detect foreground, as long as the pixel value of the detected area is matched with anyone Gaussian distribution which appearances the front Gaussian distribution of background model, we reckon the pixel is background. Otherwise it is foreground.
4.2. Edge detection method
The process of edge detection by using Canny operator mainly includes low pass filtering by Gaussian function, calculating the amplitude and direction of gradient, Non maximum suppression on the gradient amplitude, threshold and connected edge.
4.2.1. Image low pass filtering
The Canny operator firstly uses first-order derivative of 2D Gaussian function to make low pass filter to image. The 2D Gaussian function is:
4.2.2. Calculate the amplitude and direction of gradient
Using Gauss function separability, we decompose the two filter faltung template of into two one-dimensional row and column filter, and then respectively calculate faltung with image . The result is:
and respectively reflects gradient and direction angle size for of image.
4.2.3. Non maximum suppression on the gradient amplitude
It is insufficient to determine edge only by obtaining global gradient. So, we must retain the local maximum of gradient, and suppress the non-maximum. The specific procedure is traversing the image. If the gradient amplitude value of a pixel is not biggest, through comparing with its front and behind pixel at the same gradient direction, we set this pixel value as 0. That is to say, we retain only those points which have great local change at amplitude direction.
4.2.4. Threshold and edge connection
The non-maximum suppression image is made two thresholds and . They have the relation . Setting the gray level of a pixel as 0, when the pixel’s gradient value less than , we will get the image . Then setting those its gradient less than as 0, we will get the image b. Due to the reason that the two image are set different threshold, while the image is wiped off most noise, some useful edge information also is deleted and the image preserves more information. We take the image as the basic image, and then use the image to supplement and connect the edge of image. Because the traditional Canny algorithm has weak self-adaptability. We adopt the Otsu method to dynamically determine threshold, which can greatly improve the algorithm self-adaptability.
4.2.5. Otsu adaptive threshold selection
The Otsu algorithm [19-21] is considered to be the best algorithm for threshold selection in image segmentation. It has the merit of simple calculation and is not impacted by the image brightness and contrast ratio. So it has been widely applied in digital image processing. It divides image into background and foreground according to the gray characteristic. The between-cluster variance between the background and foreground is bigger and the two parts composing the image have greater difference. When a part of foreground wrongly is divided into background or a part of the background is wrongly divided into foreground, which will lead to the difference getting small. Therefore, it means the minimum mis-classification probability by using the Otsu.
The method of optimal threshold of image calculates by Otsu algorithm as follow:
and is respectively the proportion that the number of pixel of foreground and background account for the total number. and is respectively the gray level of foreground and background image.
Taking this threshold as the high threshold of Canny operator, then we use formula (20) to find the lowest threshold :
When we use the Ostu algorithm on the Canny edge detection, we can self-adaption select reasonable threshold according to the image feature, and get the result which has lesser error edge and great continuity of image border.
4.3. Continuous frame difference method
The basic principle of inter-frame difference method is subtracting the corresponding pixel value of two neighboring frame image. In the case of environmental brightness change is not great, if the corresponding pixel value has little difference, we can think the scenery is motionless. If pixel values of some region in the scene have great changes, we reckon it is caused by target motion. Then marking the pixel which has great change, we can obtain the moving target with big data by those marked pixels. The traditional adjacent frame method is easy to implement, calculating speed is fast, and having stronger robustness and self-adaption for dynamic environment. But it usually can’t absolutely extract all relevant pixels, and it is easy to cause hollow in moving targets. Based on the shortcoming of the traditional inter-frame difference method, we design the continuous frame difference method. Many experiments have showed that it can overcome the shortcomings and deficiencies of traditional inter-frame difference method in a way.
The basic principle of continuous frame difference method is: firstly, we take n continuous frame images from a video image sequence. Then, in these continuous frame images, we make subtract operation which is respectively using the pixel of different frame image and the corresponding pixel of the middle image, and then make “AND” operation for those subtraction results. Finally, we get the result of moving target with big data by adding the operation result. This method weakens the influence of environmental factors and noise on the detection of targets. In this paper, we will take continuous 7 frame image to calculate. The specific operation steps are as follows:
1) Seven successive images in the video sequence read , ,…, .
2) The difference of two adjacent frames are respectively calculated by:
3) The results of the difference make “AND” operation as:
4) These “AND” operation results are filtered, and then make the dynamic threshold value of the two treatment, finally the results were added up to obtain the target contour as:
5. Realization of the algorithm
5.1. The combination of the inter-frame difference method and the edge detection algorithm
The above two methods both can locate the moving targets accurately in the scene, but there must be a certain extent of missing. Based on the complementarity of these two methods, then combining them with each other, we can obtain the more complete target contour. The flow chart of the mixture algorithm process is shown in Fig. 2.
5.2. The combination of the inter-frame difference method and GMM
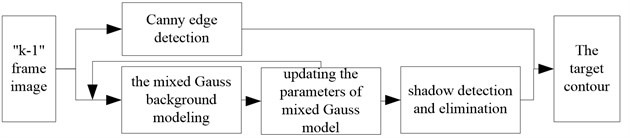
The algorithm combines the edge detection algorithm and the mixture Gauss mode. Firstly, we need modeling and updating the background during the time domain by using the mixture Gauss model, at the same time, testing the shadow by using the shadow model based on the RGB color space, and obtaining the initial shape of the moving targets. Then using the Canny edge detection algorithm to get the edge profile of the moving target with big data in a spatial domain and calculate the results which obtaining from the above two steps with logical operation “AND”, so we can getting the edge profile of the moving targets. The realization process of this algorithm is shown in Fig. 3.
Fig. 2The flow chart of the mixture algorithm process
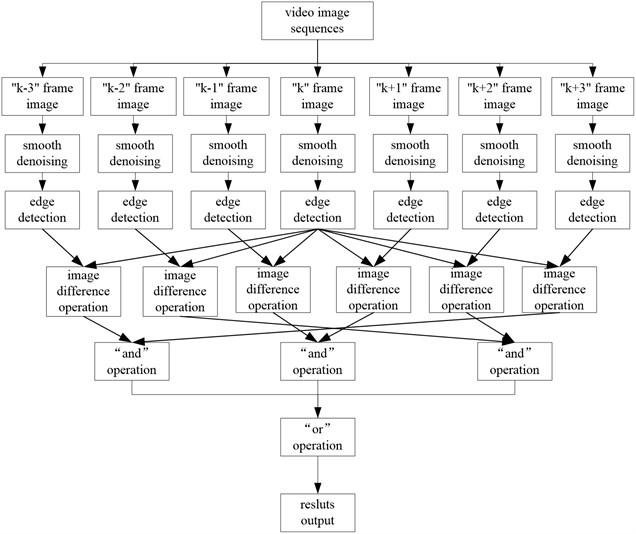
Fig. 3The realization process of this algorithm
5.3. Algorithm description
Compared with the traditional detection method about the moving targets, our algorithm can solve the leakage phenomenon to a certain extent, which is due to the targets moving slowly in the scene. In some way, it also can make up for the problem about the incomplete detection of the edge in target domain. The specific description of the algorithm in this paper is as follows.
1) Detect the contour of targets by using the algorithm which combines the mixture Gauss model with the edge detection algorithm, the specific steps of the mixture algorithm are as follows:
(1) Model and update the background in the time domain by using the mixture Gauss model.
(2) With the foreground which is extracted by using the mixture Gauss model, detecting and eliminating the shadow in the RGB color space, thus we can extract the initial foreground target.
(3) Detect the contour of the target by using the Canny edge detection algorithm.
(4) Make the initial foreground targets which obtained from the mixture Gauss model operation “AND” with the contour that calculated by the edge detection algorithm, we can get the contour of the moving targets.
2) Detect the contour of the target by using the inter-frame difference method and the edge detection algorithm, the specific steps of this mixture algorithm are as follows:
(1) Randomly select 7 consecutive frames of video images from the surveillance video.
(2) Smoothing these 7 consecutive frames in the video image respectively, which selected from the surveillance video.
(3) Detect the images which have been smoothed by using the method of edge detection algorithm.
(4) Take the images with the inter frame difference, which have been detected by the edge detection algorithm, and make the threshold binarization.
(5) Calculate the corresponding results that binarization with “AND” operation is done.
(6) And calculate three groups of results that getting from the above steps with “OR” operation.
(7) Then we can get the contour of the moving targets.
3) To calculate the results which obtained from the step 1) and step 2) with “OR” operation, we can achieve the complete contour of the moving targets after the final confirmation.
4) Dealing the detected moving targets with morphology process, we can get the final detection targets.
5.4. Shadow suppression
For the moving foreground which detected by the mixture Gauss model, we need to make shadow suppression. In a scene, due to the light source is sheltered by the targets, and a shadow is produced, and the shadow moves along with the targets. The produced shadow will change the brightness of pixel in the background image, so it is obvious that both the shadow and the moving targets will be detected as a moving foreground. Removing the shadow is the key to improve the accuracy of detection. The view experience shows that in certain brightness the tone is equal whether the target is under the shadow or not. Tone is the index to divide the category of color and we take the RGB color space as an example. We proportionally reduce all of coefficients about certain color, and darken the brightness only, keep the tone unchanged. Therefore, the relationship of brightness between inside and outside the shadow area is as follows:
After the multi-color image is converted into the gray image, the pixel values when targets are under the shadow area is times to the corresponding value in the background model ( 1), while the ratio of the brightness of foreground target with background is not a constant. Then, we can get the following formula under the illumination function:
This algorithm can effectively reduce the results of the shadow effect on target detection, among them, is real time image, is background image, and 0.79 in this paper.
5.5. Morphological processing
After we get the binary images, it usually emerges some noise due to the effect of some factors, these noise is not beneficial to analysis and study about the target which we are interested in for further steps. In order to eliminate the noise in the binary images, we can deal the binary image with the morphological process to achieve this purpose.
Firstly, we remove the isolated noise point by the corrosion operation, and then, fill the edge hole of targets by using the dilation operation. Assuming that there is a function of binary image is , the template element is , and the corrosion is defined as follows:
That is to say, the binary image which produced by the template corroding the image is a set of points: If we move from the original point to and get , will completely contain in . Under the condition of computer implementation, we put the original point of to a position in image . If all of the points in are covered by image , the point which the original of is the corresponding point that obtained from the corrosive results of , otherwise this point is not belonged to the results of . After traversing all the points in image , the trajectory of original point of is the corresponding corrosive results.
And corresponding with the corrosion, assuming that there is a function of binary image is , the template element is , and the corrosion is defined as follows:
That is to say, the binary image which produced by the template corroding the image is a set of points: If we move from original point to and get , the intersection that and is not empty. Under the condition of computer implementation, we put the original point of into a position in image . If both the points in and the corresponding points in are 1, the point which the original of is the corresponding point which obtained from the expansible results of , otherwise this point is not belonged to the results of . After traversing all the points in the image, the trajectory of original point of is the corresponding expansible results.
6. Comparisons and discussions
Simulation experiment is done in MATLAB. in order to verify the effectiveness of the proposed algorithm in this paper, we test respectively a group of AVI video sequence image by edge detection method, the mixed algorithm including three frame difference method, five frame difference and background difference algorithm, and the improved algorithm in this paper. Making the pre-treatment for each method, we can get the detected results as shown in Figs. 4-6.
Fig. 4Comparison 1 of the detected result

a) Video image sequences

b) Canny edge detection
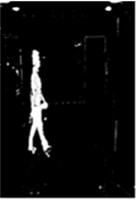
c) The three frame difference method

d) Mixed method

e) New method
As for a set of image in a video sequence, we use the algorithm proposed in this paper and a mixed method which includes the three frame difference method, the five frame difference and the background difference method to handle image. The processing results as Figs. 4-6 are shown. The traditional three frame difference method can detect the moving target with big data, but the target contour is not complete. The mixed algorithm of five frame difference method and background subtraction method can improve the continuity and integrity of target contour in a way. The target detection method in this paper can further enhance the completeness of the moving target with big data, and in large part, eliminate target cavitation. It makes the detection results become accurate, complete, clear, and can satisfy the requirement of real-time detection.
In order to analyze the algorithm in this paper, we will compare this algorithm with other algorithms with a quantitative method. Selecting consecutive frames of image from 980 to 999 in video sequences, we define two variables as follows:
represents the detected target area, represents the target area which is marked by PS4S, is precision, is recall rate. If the monitoring area and the calibration area are more consistent, the and are larger. The Figs. 7, 8 shows the curves of three kinds of algorithms.
Fig. 5Comparison 2 of the detected result

a) Video image sequences

b) Canny edge detection

c) The three frame difference method

d) Mixed method

e) New method
Fig. 6Comparison 3 of the detected result

a) Video image sequences

b) Canny edge detection

c) The three frame difference method

d) Mixed method

e) New method
Fig. 7The comparison curves on pixel number of three kinds of algorithms
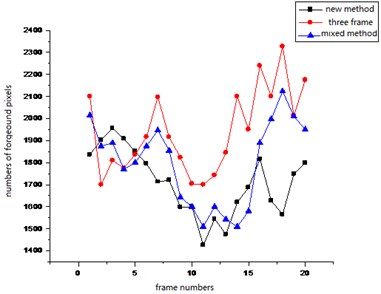
Fig. 8The comparison curves on precision of three kinds of algorithms
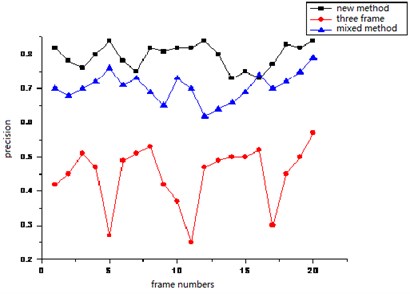
As you can see from Fig. 7, the number of foreground pixel which is obtained by the three frame difference method and the mixed algorithm including the five frame difference and the background difference method is larger than that number of pixel which is obtained by the algorithm proposed in this paper. This is mainly because the two algorithms have higher error rate through detecting the background pixel to foreground pixel than the algorithm in this paper. We can see from Figure 8 that the precision and the recall rate of the algorithm proposed in this paper are obviously much higher than the two algorithms. The superiority of the algorithm in this paper can be seen from the above quantitative contrast. In addition, we contrast the correct rate, aiming at different method of different scene at the same time range, and also contrast the complexity of the three methods, such as the following Table 1 and Table 2.
Table 1Comparison on the correct rate of different methods
Scene | Correct detection rate | ||
Three frame difference | Five frame difference and background difference method combining algorithms | The algorithm proposed in this paper | |
Corridor interior | 76.1 % | 85.4 % | 91.3 % |
Stopping place | 75.3 % | 87.1 % | 90.4 % |
Store entrance | 63.4 % | 72.5 % | 87.4 % |
Hostel entrance | 70.5 % | 81.4 % | 85.3 % |
Gymnasium interior | 74.2 % | 86.5 % | 89.4 % |
Table 2Comparison on the average time per frame detection of different methods
Scene | Average time per frame detection | ||
Three frame difference | Five frame difference and background difference method combining algorithm | The algorithm proposed in this paper | |
Corridor interior | 0.279 | 0.405 | 0.575 |
Stopping place | 0.296 | 0.397 | 0.597 |
Store entrance | 0.301 | 0.436 | 0.612 |
Hostel entrance | 0.314 | 0.425 | 0.635 |
Gymnasium interior | 0.299 | 0.417 | 0.623 |
The Table 1 and Table 2 show that in different scene the rate accuracy of the algorithm in this paper is obviously higher than the other two algorithms, especially, which is adaptive detection, and not just in edge detection - but in the detection of a walking person detection. The complexity of the algorithm in this paper decides the detection time of each frame is longer than the two methods. It also is the aspect which needs us to deeply study and improve.
7. Conclusions
We have proposed a new mixed adaptive detection algorithm based on the mixture Gauss model, the inter-frame difference method and the edge detection algorithm which is not just in edge detection – but in the detection of a walking person detection in this paper. This new algorithm makes full use of the advantages of these three algorithms effectively, detects the contour of the moving targets in the same scene by using the mixture methods which is different from each other, and then takes the contours of targets calculated by these two different algorithms with “OR” operation. Furthermore, we can achieve a more perfect contour of moving targets, and we take a method called the shadow suppression and the morphological processing. Finally, we can get the moving targets which needs to be detected in the scene. The experimental results show that this method can detect the moving target with big data accurately. And it can not only confirm the edge information of the detected moving target with big data but also complete the information, conquer some issues of the traditional algorithms that due to detecting the target incompletely, the shadow and the missing detect caused by the targets moving slowly. Besides, the calculation is simple and this new algorithm can calculate every parts at a real time.
References
-
Zhang D. G., Kang X. J. A novel image de-noising method based on spherical coordinates system. EURASIP Journal on Advances in Signal Processing, Vol. 110, 2012, p. 1-10.
-
Zhang D. G., Li G. An energy-balanced routing method based on forward-aware factor for wireless sensor network. IEEE Transactions on Industrial Informatics, Vol. 10, Issue 1, 2014, p. 766-773.
-
Ji X. P., Wei Z. Q., Feng Y. W. Effective vehicle detection technique for traffic surveillance systems. Visual Communication Image Represent, Vol. 17, 2006, p. 3-647.
-
Stauffer C., Grimson W. E. L. Adaptive background mixture models for real-time tracking. IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Vol. 2, 1999, p. 246-252.
-
Zhang D. G., Wang X. A novel approach to mapped correlation of ID for RFID anti-collision. IEEE Transactions on Services Computing, Vol. 7, Issue 4, 2014, p. 741-748.
-
Jodoin P. M., Mignotte M., Konrad J. Statistical background subtraction using spatial cues. IEEE Transactions on Circuits and Systems for Video Technology, Vol. 17, Issue 12, 2007, p. 1758-1763.
-
Zhang D. G., Song X. D., Wang X. Extended AODV routing method based on distributed minimum transmission (DMT) for WSN. International Journal of Electronics and Communications, Vol. 69, Issue 1, 2015, p. 371-381.
-
Zhang D. G., Song X. D., Wang X., li K., Li W. B., Ma Z. New agent-based proactive migration method and system for big data environment (BDE). Engineering Computations, Vol. 32, Issue 8, 2015, p. 2443-2466.
-
Grimson W. E. L., Stauffer C., Romano R., et al. Using adaptive tracking to classify and monitor activities in a site. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 1998, p. 22-29.
-
Collins R. T., Lipton A., Kanade T., et al. A System for Video Surveillance and Monitoring. Carnegie Mellon University, The Robotics Institute, Pittsburg, 2000.
-
Murray D., Basu A. Motion tracking with an active camera. IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 16, Issue 5, 1994, p. 449-459.
-
Ronghua L., Huaqing M. Mixture conditional random fields for multi-object tracking with a mobile robot. International Conference on Information and Automation, 2010, p. 391-396.
-
Zhang D. G., Zhao C. P. A new medium access control protocol based on perceived data reliability and spatial correlation in wireless sensor network. Computers and Electrical Engineering, Vol. 38, Issue 3, 2012, p. 694-702.
-
Zhang D. G., Zhang X. D. Design and implementation of embedded un-interruptible power supply system (EUPSS) for web-based mobile application. Enterprise Information Systems, Vol. 6, Issue 4, 2012, p. 473-489.
-
Zhang D. G. A new approach and system for attentive mobile learning based on seamless migration. Applied Intelligence, Vol. 36, Issue 1, 2012, p. 75-89.
-
Cucchiara R., Grana C., Piccardi M., et al. Detecting moving objects, ghosts and shadows in video streams. IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 25, Issue 10, 2003, p. 1337-1342.
-
Zhang D. G., Zhu Y. N. A new constructing approach for a weighted topology of wireless sensor networks based on local-world theory for the internet of things (IOT). Computers and Mathematics with Applications, Vol. 64, Issue 5, 2012, p. 1044-1055.
-
Ha J. E. Foreground objects detection using multiple difference images. Optical Engineering, Vol. 49, Issue 4, 2010, p. 1-5.
-
Zhang D. G., Liang Y. P. A kind of novel method of service-aware computing for uncertain mobile applications. Mathematical and Computer Modeling, Vol. 57, Issues 3-4, 2013, p. 344-356.
-
Ojala T., Pietukainen M., Maenpaa T. Multi-resolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 24, Issue 7, 2002, p. 971-987.
-
Zhang D. G., Zheng Ke, Zhang Ting A novel multicast routing method with minimum transmission for WSN of cloud computing service. Soft Computing, Vol. 19, Issue 7, 2015, p. 1817-1827.
-
Zhang D. G., Zheng Ke, Zhao De-Xin, Song X. D., Wang X. Novel quick start (QS) method for optimization of TCP. Wireless Networks, Vol. 22, Issue 1, 2016, p. 211-222.
-
Meyer D., Denzler J., Niemann H. Model based extraction of articulated objects in image sequences for gait analysis. Proceedings of the International Conference on Image Processing, Vol. 3, 1997, p. 78-81.
-
Zhang D. G., Wang X., Song X. D., Zhang T., Zhu Y. N. New clustering routing method based on PECE for WSN. EURASIP Journal on Wireless Communications and Networking, Vol. 162, 2015, p. 1-13.
-
Lipton A. J., Fujiyoshi H., Patil R. S. Moving target classification and tracking from real-time video. Proceedings of the International Conference on Applications of Computer Vision, 1998, p. 8-14.
-
Zhang D. G., Li W. B., Liu S. Novel fusion computing method for bio-medical image of WSN based on spherical coordinate. Journal of Vibroengineering, Vol. 18, Issue 1, 2016, p. 522-538.
About this article

This study was funded by National Natural Science Foundation of China (Grant Nos. 61170173 and 61571328), Tianjin Key Natural Science Foundation (No. 13JCZDJC34600), Major Projects of Science and Technology in Tianjin (No. 15ZXDSGX00050), Training Plan of Tianjin University Innovation Team (No. TD12-5016), Major Projects of Science and Technology for their services in Tianjin (No. 16ZXFWGX00010), Training Plan of Tianjin 131 Innovation Talent Team (No. TD2015-23).
