Abstract
The health condition assessment of Electric Multiple Unit (EMU) traction motor ball bearing is one of the key issues of high-speed train running safety. In order to assess health condition of EMU traction motor ball bearing, an online-sequential extreme learning machine algorithm based on TensorFlow (TOSELM) is proposed. Samples data set is divided into normal condition and fault condition using vibration data of ball bearings. This paper uses health condition accuracy rate index to evaluate TOSELM algorithm performance. The proposed approach is verified by public data set and private data set. The experiment results show the proposed method is an effective method for ball bearing health status assessment.
1. Introduction
The bearing vibration data can reflect healthy state of the high-speed train bearing. Therefore, it is of great significance to analyze the vibration data of high-speed train bearing to ensure the safe operation of the high-speed train. Vibration analysis is widely applied in the health condition assessment of ball bearings [1-18]. For example, Ahmadian uses two layer BP neural network and ultrasonic acoustic emissions to classify the health condition of ball bearings [14]. Deepak makes use of BP neural network to classify rolling ball bearing faults and discusses the effect of neural network parameter [15, 16]. But BP method need a lot of human labor to achieve good classification accuracy. Some scholars have improved it. For instance, Lei et al. propose a two-stage intelligent fault diagnosis method to classify the bearing health conditions [17]. The proposed neural network method directly learns features from raw vibration data and does not require human intervention. Tong puts forward a hybrid method using singular value decomposition and extreme learning machine to diagnose the faults of rolling ball bearings [18]. The experiment result is good, but need much time to extract fault feature. In brief, the above stated methods can get a good result, but they need a lot of human labor to extract feature and optimize algorithm parameters or require a lot of program running time.
On the other hand, with new technologies, such as internet of things, big data, and wide applications of sensor, data volume has grown in an exponential manner. Big data analysis can discover insights from a huge volume of data and increasingly drives decision making in various industries, including the bearing’s health assessment [19]. The methods above processing big vibration data from the sensors, exposed many shortcomings such as the long processing time, many manual interventions and so on. Some scholars have made a valuable exploration of the methods of large data analysis. For example, Akusok et al. develop a HP-ELM toolbox for big data applications [20]. So, big vibration data analysis need a high demand for computing efficiency and computing method. HP-ELM toolbox is suitable for off-line classification problems, but it is not suitable for solving online classification problems. How to solve the evaluation of the health condition of on-line big bearing vibration data is a key issue? This paper attempts to solve this challenging problem on TensorFlow platform. TOSELM method based deep learning system will be introduced to effectively handle the EMU ball bearings health condition assessment.
The remainder of this paper is organized as follows. In Section two, The BP, ELM and OS-ELM algorithms are introduced briefly. Then, this paper describes data, extracts statistical features from data and briefly explains the concept of TensorFlow. TOSELM method is developed using TensorFlow system in section three. In Section four, to assess health condition of ball bearing, experiment and discussion of BP, ELM and TOSELM are conducted. Finally, conclusions are given in the last section.
2. Related work
Classification is the most commonly technique used analysis health status. The BP, ELM and OS-ELM algorithm can be used for classification; therefore, the three algorithms are feasible for evaluating the health status of ball bearings. This section is dedicated as BP, ELM and OS-ELM algorithm review. In this section, brief review of these algorithms, working process and characteristics are presented.
2.1. BP neural network
BP neural network was proposed by the research team headed by Rumelhart and McCelland in 1986 [21]. BP neural network is a multi-layer feedforward neural network. BP is an iterative learning algorithm, which uses generalized perceptual learning rules to update parameters in each round of the iteration. BP algorithm is based on gradient descent strategy to adjust the parameters in the negative gradient direction of the target. It is one of the most widely used neural network models.
The main characteristic of BP is that the signal is transmitted forward and the error is back propagation. In forward transfer, the input signal is processed layer by layer from the input layer through the hidden layer until the output layer. The neuron status at each level affects only the next layer of neurons. If the output layer predictive value cannot get the desired output value, then it goes to back propagation and adjusts the weights and thresholds of each layer of the network according to prediction error. After several iterations, the predicted output of BP neural network approaches the expected output. The topology structure of BP neural network is shown in Fig. 1. , , …, are the input value, , , …, are the predictive value, and and is the network node weight in Fig. 1.
Fig. 1The topology structure of BP neural network
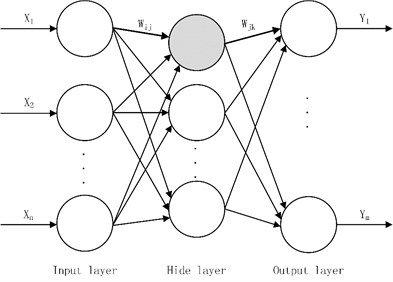
BP neural network can be regarded as a nonlinear function, and the input and predictive values of the network are independent variables and dependent variables respectively. When the input node number is and the output node number is , the BP neural network expresses the function mapping relationship from independent variables to dependent variables. In the design of BP network, it is generally considered from several aspects such as the number of layers in the network, the number of neurons in each layer, the activation function, the initial value, and the learning rate.
The disadvantage of BP neural network is slow convergence, large amount of calculation, long training time, easy to fall into local minimum and not interpretable.
2.2. ELM
ELM is a new neural network algorithm proposed by Huang [23]. Compared with the traditional neural network, ELM training speed is very fast and require less manual interference. The algorithm has a strong generalization ability.
From the point of view of the neural network structure, ELM is a simple single hidden layer feedforward networks(SLFN). SLFN is shown in Fig. 2.
Fig. 2The topology structure of SLFN neural network
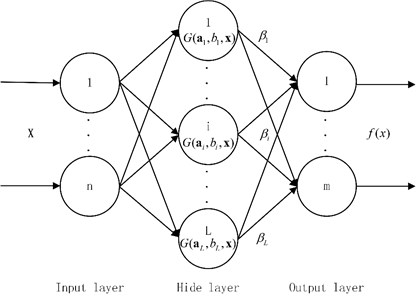
For a single hidden layer neural network, it is assumed that there are arbitrary samples (, ), where , . For a hidden layer network with hidden layer nodes, the neural network can be represented as follow where represents the connection weight between the hidden layer neuron and the output neuron. It is a weight vector of the dimension. is the output of the hidden layer neuron. Parameters of the hidden layer node are and . When the hidden layer nodes are additive type, where is the activation function. The input weight is . The bias of the th hidden layer node is . The output function of the neural network can be written as follows:
where:
When is equal to , Eq. (1) must have a solution. However, in practical problems, is often much smaller than , that is, there is an error between the network output and the actual output, then the cost function can be defined as: . How do we solve the optimal weight vector to minimize the loss function ? ELM algorithm solves this problem in two situations:
A) If is a column full rank, the best weight can be found by the least square. The solution is:
where .
B) If is not column full rank, singular value decomposition is used to solve the generalized inverse of to compute the optimal weight.
BP uses gradient descent iterations to update the weights between all layers, while ELM does not adjust the weights of the input layer and the hidden layer. These weights are randomly assigned, so the training speed of ELM is very fast. Many experimental results suggest that ELM algorithm has higher learning speed and generalization performance compared with the standard BP algorithm.
2.3. OS-ELM
The on-line sequential extreme learning machine (OS-ELM) is one of the improved extreme learning machine (ELM) algorithms [20], [22-24]. It has been widely used in data fitting, classification forecasting and other fields. OS-ELM algorithm is based on single hidden layer feedforward neural networks(SLFN). So, a brief introduction of OS-ELM is given first. The output of a single hidden layer feedforward neural networks with hidden nodes can be represented by:
where the nodes number in hidden layer is , the connection weight of the input layer and the hidden layer is and the hidden layer threshold is . The output weights of the th hidden layer nodes to the output nodes is . The input data is and the output data is . Assume that the input samples are , and the training set of the th samples is represented as:
where the input sample number is and the number of classification is .
OS-ELM algorithm includes random initialization phase and online continuous learning phase. OS-ELM algorithm is described as follows.
2.3.1. Random initialization phase
Select a partial data set from , where represents the initial number selected, and is not less than . Hidden layer input weights and hide Layer threshold are generated randomly. Calculate the output matrix of the initial hidden layer :
It is known that the target output is . . To calculate the initial output weight value is equaled to calculate the minimum value of . Eq. (1) can be written compactly matrix form , thus . According to matrix theory, we have the minimal solution:
From the equation . For the sake of convenient expression, Eq. (4) is rewritten as follows where .
2.3.2. Online continuous learning phase
When the ( 1)th sample data is received, we can calculate the output matrix of the hidden layer, get from Eq. (3):
where the unit matrix is . Therefore, the new output weight can be got from Eq. (4):
3. TOSELM model
This paper uses Case Western Reserve University (CWRU) normal and faulty ball bearing test public data sets and private data sets to illustrate the effectiveness of the proposed algorithm [25].
3.1. Data description
CWRU ball bearing experiments were conducted using a 2 hp Reliance Electric motor, and acceleration data was acquired from the motor bearings. Experimental data consists of two categories: one is the normal data and the other is the fault data. The latter include inner race fault, outer race fault and ball fault. Faults ranging from 0.007 inches to 0.040 inches in diameter were introduced separately at the inner raceway, rolling element and outer raceway. Vibration fault data was recorded for motor speeds from 1797 to 1730 RPM.
The industrial ball bearing test of high speed train is carried out on NTN traction motor bearing test rig. The ball bearings used in specific type high-speed train is NTN 6311 deep groove ball bearings. In this paper, NTN 6311 ball bearing is tested on test rig. Acceleration sensor was used to collect the operation information of NTN 6311 deep groove ball bearings in order to monitor its health state. The test bearing runtime accumulates 732 hours on the test rig with a cumulative mileage of nearly 300,000 kilometers. The collected data can be divided into two types: radial vibration data of fault ball bearing and radial vibration data of normal ball bearing.
3.2. Feature extraction
The public ball bearing vibration data acquired from Case Western Reserve University Bearing Data Center. This data set has many vibration data files. This paper extracts features from the raw sensory data: B007-1.mat, B014-1.mat, Normal-1.mat, IR007-1.mat, IR014-1.mat, IR021-1.mat, 1772.mat, OR007@6-1.mat, OR014@6-1.mat, OR021@6-1.mat.
One of the challenges of assessing health condition of ball bearing lies in extracting the right correlated features. In order to obtain more comprehensive and accurate running health information and take account of the computation time, this paper selects the following features. The features include: maximum absolute value, absolute mean, peak-peak value, square mean root, kurtosis, crest factor, kurtosis factor, impulse factor, clearance factor and shape factor. The description and equations are shown in Table 1.
Absolute mean represents the vibration signal amplitude absolute mean value. It is used to describe the stability of signals. Maximum absolute value denotes the maximum amplitude value of the vibration signal waveform. Peak-peak value describes the range of signal values. Square mean root represents the vibration signal energy and its stability and repeatability are better. The larger the kurtosis indicates the more impulse component in the vibration signal. Crest factor is an important parameter to reflect the development trend of bearing faults. The kurtosis factor, impulse factor and clearance factor can effectively diagnose the incipient impulse faults. Shape factor has good stability and poor sensitivity. These features are fast and useful calculation index that can indicate the bearing health condition using vibration big data. The ten features were referred as features in this paper. Features are used to test the health state of ball bearings.
Table 1Features of vibration data
Feature | Equation | Feature | Equation |
Absolute mean | Crest factor | ||
Max absolute value | Kurtosis factor | ||
Peak-peak value | Impulse factor | ||
Square mean root | Clearance factor | ||
Kurtosis | Shape factor | ||
Note: is the vibration signal , is the mean of , | |||
3.3. TOSELM algorithm
Many applications of OS-ELM are running in a single computer environment. When dealing with high-speed train vibration big data, it is not only time-consuming, but also not well suited to the needs of the high-speed train business. This paper develops OS-ELM algorithm through TensorFlow open source software library, in order to improve the algorithm adaptability to huge ball bearings vibration data.
TensorFlow was originally developed by the Google Brain team. It released on November 9, 2015. TensorFlow is an open source software library for machine learning. The system is flexible and can be used to develop a variety of algorithms for deep neural network models [26]. It is a complete coding framework. TensorFlow computation tasks are expressed as data flow graphs. TensorFlow has its own definitions of constants, variables, and data operations. It uses session to execute the graph.
In order to make good use of TensorFlow framework processing vibration big data, this paper proposes an improved OS-ELM algorithm named TOSELM on TensorFlow deep learning system. How does TensorFlow framework deal with ball bearing vibration big data? There are three kinds of technologies: batch generator, mutation and data flow graph can help solve this challenging problem. Tensorflow provides batch generator to process big data. First, it put the data into the queue. Second, select a TensorFlow reader, and then read the data from the queue, finally use the tf.train.batch or tf.train.shuffle_batch in order to generate custom batch size data. Meanwhile, TensorFlow introduces the concept of mutation. By mutation, it can change a variable value in the computation process, and the variable is carried into the next iteration. The concept of mutation is very consistent with the operation requirements of OSELM algorithm. The biggest characteristic of TensorFlow is the data flow graph. The data flow graph is a directed graph. The nodes in the graph represent the operations, and the edges between nodes represent the multidimensional array data involved in the computation. Tensor is the multidimensional array data. Tensor can have any dimension, and each dimension can have any length. The execution of computational graph can be regarded as the process of data flow from the input node gradually to all the intermediate nodes, and finally to the output node. TensorFlow provides great space and freedom for data calculation through data flow graph, and ensures the flexibility of algorithm implementation. Data flow graph can be used to express computation intuitively. In order to use the data flow graph, each node is symbolized, and the data flow direction indicates the order of computation process. TOSELM algorithm is shown in Table 2.
Table 2TOSELM algorithm
Input: |
Create a data flow graph through session; |
The training data set , ; |
The number of hidden layer nodes ; |
The training data block 1; |
Output: |
Randomly generated hidden layer input weight , hidden layer threshold ; |
Calculates the initial hidden layer output matrix according to Eq. (3); |
Calculate the initial output weight according to Eq. (4); |
The hidden layer output matrix is computed with incremental data block 1; |
is calculated according to Eq. (5) and Eq. (6); |
) is calculated according to Eq. (6); |
Return ; Call session.run to perform the calculation. |
4. Experiment and discussion
Bearing health condition assessment is a key issue of EMU condition-based maintenance. The assessment bearing health condition using vibration data has been a research topic for many years. It includes two mainstream methods: signal processing methods and classification algorithms [27]. This paper uses the latter.
This paper proposes the below process to access the health condition of ball bearings as shown in Fig. 3. The Experiments were conducted on Case Western Reserve University ball bearing test data and NTN 6311 ball bearing test data. The selected bearings were tested on these experimental setups and the vibration signals were acquired at defined intervals. Then, the signals are converted to data for further analysis.
Statistical features were deployed for feature extraction. Features are used as model input.
Fig. 3Flowchart of the proposed method

The BP, ELM and TOSELM model will be used for assessing the ball bearings health condition. The proposed method was tested with the vibration data of ball bearings from Case Western Reserve Lab. To compare three algorithms performance, test accuracy and test run time are adopted. Accuracy is a criterion measuring the performance of a classification method. Model running time is an important algorithm index. If some models perform the same function and process the same data, the shorter running time model is the best. The program run time and ten-fold cross-validation test results of BP, ELM and TOSELM are shown in Table 3.
The classification accuracy and average accuracy of the 10-fold cross validation test data set of BP, ELM, and TOSELM is in the left part of Table 3. From the average accuracy of the three algorithms, it can be seen that average test accuracy of ELM is 3.64 % higher than that of BP; the average test accuracy of TOSELM is 0.08 % higher than that of ELM. On the whole, TOSELM average test accuracy rate is the highest, ELM is the second, and BP is the lowest. From the right part of Table 3, one can see the running time and the corresponding average run time of the 10-fold cross validation test data set of BP, ELM and TOSELM. From the three algorithms run time, it can be seen that average test running time of ELM is 0.778 seconds faster than that of BP; average test running time of TOSELM is 0.002 seconds faster than that of ELM. Overall, the average running time of TOSELM is the least. From the above analysis results, we can see that TOSELM is the most suitable algorithm for evaluating the health condition of ball bearings in three algorithms.
A group of experiments were conducted, in order to evaluate the feasibility of BP, ELM and TOSELM on high-speed train. The experimental results are shown in Table 4. From the left part of Table 4, it can be seen that average test accuracy of ELM is 4.46 % higher than that of BP; the average test accuracy of TOSELM is 0.92 % higher than that of ELM. On the whole, TOSELM average test accuracy rate is the highest compared with BP and ELM. From the right part of Table 4, it can be seen that the running time of BP, ELM and TOSELM is 37.075 seconds, 2.667 seconds and 2.485 seconds respectively. Overall, the average running time of TOSELM is the least.
According to the above experimental results of Table 3 and Table 4, one can clearly see that TOSELM model evaluates the ball bearing health condition with a higher accuracy and shorter time, compared with BP and ELM. However, as the volume of data increases, the noise increases, which results in a lower test accuracy on NTN 6311 test set than that in Case Western Reserve University ball bearing test set. These results support the claims that TOSELM model is useful for the health condition assessment of high-speed train ball bearings.
Table 3The program test run time and test accuracy of CWRU ball bearing test data
ID | Test accuracy | Test run time | ||||
BP | ELM | TOSELM | BP | ELM | TOSELM | |
1 | 93.08 % | 100 % | 100 % | 0.986 | 0.044 | 0.078 |
2 | 94.23 % | 100 % | 100 % | 0.908 | 0.051 | 0.041 |
3 | 95.38 % | 100 % | 98.46 % | 0.910 | 0.042 | 0.042 |
4 | 96.15 % | 98.46 % | 100 % | 0.057 | 0.046 | 0.048 |
5 | 96.77 % | 100 % | 100 % | 0.890 | 0.050 | 0.040 |
6 | 96.67 % | 100 % | 100 % | 0.903 | 0.044 | 0.044 |
7 | 96.81 % | 100 % | 100 % | 0.917 | 0.045 | 0.044 |
8 | 97.02 % | 99.23 % | 100 % | 0.906 | 0.079 | 0.035 |
9 | 97.18 % | 100 % | 100 % | 0.884 | 0.037 | 0.035 |
10 | 97.23 % | 99.23 % | 99.23 % | 0.895 | 0.035 | 0.041 |
Average | 96.05 % | 99.69 % | 99.77 % | 0.825 | 0.047 | 0.045 |
Table 4The program test run time and test accuracy of EMU ball bearing test data
ID | Test accuracy | Test run time | ||||
BP | ELM | TOSELM | BP | ELM | TOSELM | |
1 | 100.00 % | 98.75 % | 99.00 % | 35.051 | 2.924 | 2.292 |
2 | 75.00 % | 93.75 % | 98.75 % | 90.612 | 2.830 | 2.272 |
3 | 83.33 % | 93.75 % | 93.75 % | 7.881 | 2.646 | 2.352 |
4 | 87.50 % | 91.25 % | 98.75 % | 91.858 | 2.536 | 2.500 |
5 | 90.00 % | 83.75 % | 88.75 % | 12.057 | 2.624 | 2.538 |
6 | 91.67 % | 92.50 % | 91.25 % | 8.471 | 2.587 | 3.258 |
7 | 92.86 % | 96.25 % | 77.50 % | 10.975 | 2.847 | 2.449 |
8 | 87.50% | 92.50 % | 98.75 % | 86.448 | 2.640 | 2.260 |
9 | 88.89 % | 96.25 % | 95.00 % | 20.045 | 2.544 | 2.607 |
10 | 90.00 % | 92.50 % | 99.00 % | 7.348 | 2.489 | 2.316 |
Average | 88.67 % | 93.13 % | 94.05 % | 37.075 | 2.667 | 2.485 |
5. Conclusions
This paper proposes a health condition assessment model. It can address bearing health condition assessment issue that suits to a real time big data application. The proposed model is effective in removing the influence introduced by the operation condition environment and improves the robustness in the bearing health condition assessment. The analysis of the practical vibration data demonstrated that the proposed index group is feasible and effective to indicate the health condition of the EMU bearing. Overall, the obtained results are important enough for further development of health condition assessment of ball bearings system and the proposed approach can be useful reference for specialists working in this field.
References
-
Wang D., Qin Y., Cheng X., et al. Train rolling bearing degradation condition assessment based on local mean decomposition and support vector data description. Proceedings of the International Conference on Electrical and Information Technologies for Rail Transportation, 2017, p. 177-186.
-
Liao L., Jin W., Pavel R. Enhanced restricted Boltzmann machine with prognosability regularization for prognostics and health assessment. IEEE Transactions on Industrial Electronics, Vol. 63, Issue 11, 2016, p. 7076-7083.
-
Kulkarni P. G., Sahasrabudhe A. D. Investigations on mother wavelet selection for health assessment of lathe bearings. International Journal of Advanced Manufacturing Technology, Vol. 90, Issues 9-12, 2016, p. 1-15.
-
Jiang H., Chen J., Dong G. Hidden Markov model and nuisance attribute projection based bearing performance degradation assessment. Mechanical Systems and Signal Processing, Vol. 72, 2016, p. 184-205.
-
Li H., Wang Y., Wang B., et al. The application of a general mathematical morphological particle as a novel indicator for the performance degradation assessment of a bearing. Mechanical Systems AND Signal Processing, Vol. 82, 2016, p. 490-502.
-
Ma L., Zhang T. Health status identification of rolling bearing based on SVM and improved evidence theory. IEEE International Conference on Software Engineering and Service Science, 2016, p. 378-382.
-
Zhou T., Hu P. A rolling bearing health status assessment method based on support vector data description. Vibroengineering Procedia, Vol. 10, 2016, p. 179-184.
-
Jiang H., Chen J., Dong G., et al. An intelligent performance degradation assessment method for bearings. Journal of Vibration and Control, Vol. 23, Issue 18, 2017, p. 3023-3040.
-
Zhou J., Guo H., Zhang L., et al. Bearing performance degradation assessment using lifting wavelet packet symbolic entropy and SVDD. Shock and Vibration, Vol. 6, Issue 2016, 2016, p. 1-10.
-
Wang B., Hu X., Li H. Rolling bearing performance degradation condition recognition based on mathematical morphological fractal dimension and fuzzy C-means. Measurement, Vol. 109, 2017, p. 1-8.
-
Yu J. Adaptive hidden Markov model-based online learning framework for bearing faulty detection and performance degradation monitoring. Mechanical Systems and Signal Processing, Vol. 83, 2017, p. 149-162.
-
Zhao F., Chen J., Guo L., et al. Neuro-fuzzy based condition prediction of bearing health. Journal of Vibration and Control, Vol. 15, Issue 7, 2009, p. 1079-1091.
-
Miao Q., Tang C., Liang W., et al. Health assessment of cooling fan bearings using wavelet-based filtering. Sensors, Vol. 13, Issue 1, 2013, p. 274-291.
-
Kirchner W., Southward S., Ahmadian M. Ultrasonic acoustic health monitoring of ball bearings using neural network pattern classification of power spectral density. Proceedings of SPIE the International Society for Optical Engineering, Vol. 7650, Issue 1, 2010, p. 255-265.
-
Gaud D. K., Jayaswal P. Effects of artificial neural network parameters on rolling element bearing fault diagnosis. International Journal of Current Engineering and Scientific Research, Vol. 3, Issue 1, 2016, p. 55-60.
-
Gaud D. K., Agrawal P., Jayaswal P. Fault diagnosis of rolling element bearing based on vibration and current signatures: An optimal network parameter selection. International Conference on Electrical, Electronics, and Optimization Techniques, 2016, p. 4065-4069.
-
Lei Y., Jia F., Lin J., et al. An intelligent fault diagnosis method using unsupervised feature learning towards mechanical big data. IEEE Transactions on Industrial Electronics, Vol. 63, Issue 5, 2016, p. 3137-3147.
-
Tong Q., Cao J., Han B., et al. A fault diagnosis approach for rolling element bearings based on rsgwpt-lcd bilayer feature screening and extreme learning machine. IEEE Access, Vol. 5, Issue 1, 2017, p. 5515-5530.
-
Qin S. J. Process data analytics in the era of big data. AIChE Journal, Vol. 60, Issue 9, 2014, p. 3092-3100.
-
Akusok A., Bjork K. M., Miche Y., et al. High-performance extreme learning machines: a complete toolbox for big data applications. IEEE Access, Vol. 3, 2015, p. 1011-1025.
-
Rumelhart D. E., Hinton G. E., Williams R. J. Learning representations by back-propagating errors. Nature, Vol. 323, Issue 6088, 1986, p. 533-536.
-
Liang N. Y., Huang G. B., Saratchandran P., et al. A fast and accurate online sequential learning algorithm for feedforward networks. IEEE Transactions on Neural Networks, Vol. 17, Issue 6, 2006, p. 1411-1423.
-
Huang G., Zhu Q., Siew C. Extreme learning machine: a new learning scheme of feedforward neural networks. IEEE International Joint Conference on Neural Networks, 2004, p. 25-29.
-
Huang G. B., Zhu Q. Y., Siew C. K. Extreme learning machine: Theory and applications. Neurocomputing, Vol. 70, Issues 1-3, 2006, p. 489-501.
-
Ball bearing test data for normal and faulty bearings. Case Western Reserve University Bearing Data Center, http://csegroups.case.edu/bearingdatacenter.
-
Abadi M. I. N., Agarwal A., Barham P., et al. Tensorflow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. 2015, tensorflow.org.
-
Siegel D., Al Atat H., Shauche V., et al. Novel method for rolling element bearing health assessment – a tachometer-less synchronously averaged envelope feature extraction technique. Mechanical Systems and Signal Processing, Vol. 29, 2012, p. 362-376.
About this article

This research was partially supported by the National High Technology Research and Development Program of China (863 Program) (No. 2015AA040701), Science and Technology Research and Development Project of China Railway Corporation (No. 2015J008-A), and Beijing Natural Science Foundation (No. 3162023). The authors appreciate the High-Performance Computing Center of Hebei University for providing the experimental environment.
Professor Liu Feng provided basic ideas. Qingbin Tong and Qiming Niu discussed and provided many constructive suggestions. Junci Cao provided and preprocessed the bearing data of Case Western Reserve University. Yihuang Zhang conducted practical experiment and provided the actual data.
